 Shadows Online
Shadows Online
Trouver son chemin LDVELH
Pour commencer un petit programme ldvelh-graphviz.py permettant d’afficher le diagramme de dépendance des numéros d’un livre dont vous êtes le héros.
Vopyons comment fonctionne l’outil sur le livre-jeu l’homme qui goûtait à ses propres Macédoines...
Tout d’abord il faut créer un fichier macedoines.py contenant les relations entre les numéros / chapitres :
NODES = { 0: { 'name': "L'homme qui goutait a ses propres Macedoines",
'description': "Une aventure pour illustrer le concept de linearite des livres-jeux." },
}
EDGES = {
1: [3, 7],
2: [6, 12],
3: [4, 6, 11],
4: [2, 12],
6: [12],
7: [8, 9],
8: [10],
9: [10],
10: [5],
11: [4, 12],
}On peut alors afficher le graphe :
$ python ldvelh-graphviz.py --graph macedoines --graphviz macedoines.dot
Writing 'macedoines.dot'...
$ dot -Tpng -o macedoines.png macedoines.dot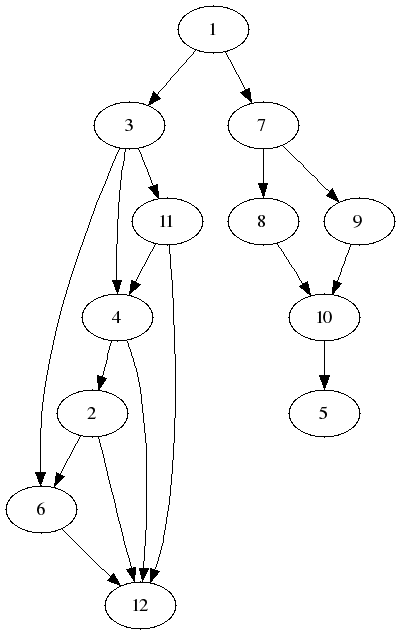
Ensuite, on peut exploiter ce graphe afin de trouver les chemins du numéro 1 jusqu’au numéro 12 par exemple :
$ python ldvelh-graphviz.py --graph macedoines --start 1 --end 12 --first
find_first_path:
[1, 3, 4, 2, 6, 12] (6)
0.000131762555929 s
$ python ldvelh-graphviz.py --graph macedoines --start 1 --end 12 --shortest
find_shortest_path:
[1, 3, 4, 12] (4)
0.000152619442922 s
$ python ldvelh-graphviz.py --graph macedoines --start 1 --end 12 --all
find_all_paths:
[[1, 3, 4, 2, 6, 12], [1, 3, 4, 2, 12], [1, 3, 4, 12], [1, 3, 6, 12], [1, 3, 11, 4, 2, 6, 12], [1, 3, 11, 4, 2, 12], [1, 3, 11, 4, 12], [1, 3, 11, 12]] (8)
0.000183739242564 sCf. python ldvelh-graphviz.py --help pour l’aide.